



Geospatial Sovereignty in the Age of AI: A Layered Approach





.png)
On my last trip to Japan, I visited one of my favourite museums, the Tokyo National Museum. I was admiring a fascinating, 200-year-old illustrated map of the Tōkaidō highway, a relic from the Edo period.
This era is famous for Japan’s sakoku or “closed country” policy, a time when it was largely seen as isolated from the rest of the world. But this is a common misunderstanding. The shogunate's policy wasn't about total isolation; it was about strict control over its borders and trade, choosing exactly how and with whom it would engage.
It struck me as a powerful historical lens for one of today's most urgent debates. The push for “technological sovereignty” has become one of the most pressing topics in boardrooms and government cabinets worldwide. What was once a niche concern for defense agencies is now a core strategic priority across critical industries and public sectors.
The momentum is undeniable. Europe’s EuroStack initiative aims to build fully sovereign digital infrastructure. Saudi Arabia’s Data & AI Authority (SDAIA) is developing comprehensive data sovereignty frameworks as part of Vision 2030. These aren’t fringe movements; they’re strategic national priorities reshaping how we think about digital infrastructure.
Perhaps no nation has acted on this more decisively than Estonia. Years ago, it established the world's first "Data Embassy" in Luxembourg, a state-owned, sovereign extension of its government cloud, legally protected with diplomatic immunity. And what data did they include in that embassy? A lot of geospatial data, including the land registry, population registry, and State Gazette.
In my conversations with leaders across Europe, the Middle East, and the Americas, the same themes emerge: a growing urgency to reassess dependencies, ensure resilience against outages, and maintain control over critical digital infrastructure.
Nowhere is this more critical than in the geospatial world. Spatial data is the “where” that underpins everything from national security and critical infrastructure to urban planning and environmental monitoring. As this data becomes the lifeblood of AI-driven systems, architecting for sovereignty isn’t just prudent, it’s imperative.
Now, I often hear political discussions about digital sovereignty and big plans to make it happen. But what you don't hear very often is how to make it happen under the hood. Especially when it comes to data analytics. Although we still have a lot of things to make it happen, overall, there is enough of a foundation to have a decent technology architecture. Of course, there is more to sovereignty than the technical architecture, with things like people enablement or legislation, but I will focus here mostly on the technology aspect and my vision for a successful strategy that does not end up in isolation. Let´s get started.
Here’s the key insight. Sovereignty doesn’t mean building walls or rejecting innovation. True sovereignty is about choice. It’s about having the architectural flexibility to use the best technology available, whether from Google, AWS, or your own data center, without getting locked into a single vendor or ecosystem. This also means having the possibility to use the latest technologies and innovation where adequate, securely.
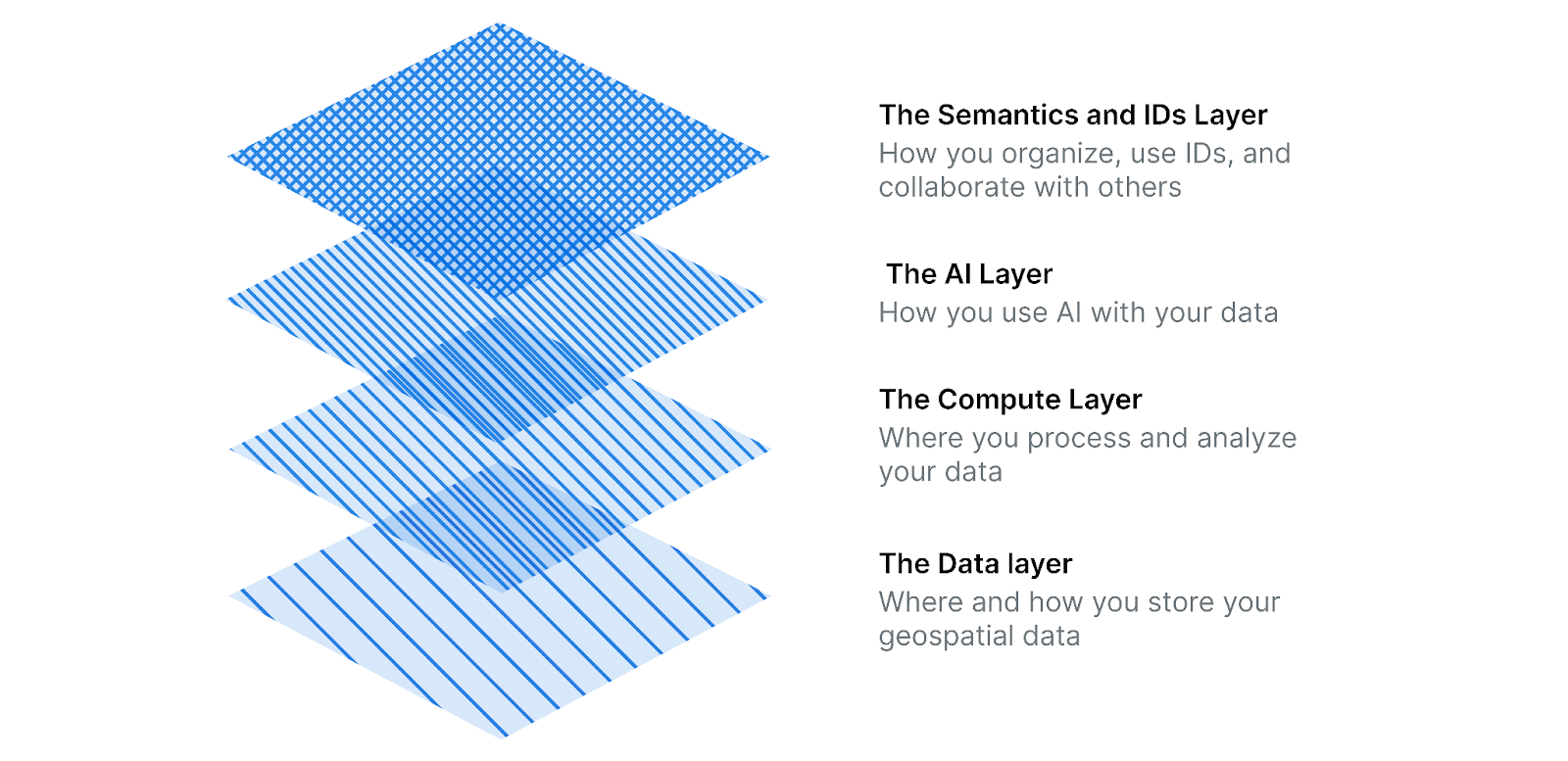
This is achieved by thinking of sovereignty not as a single product, but as a layered stack.
- The Data layer: Where and how you store your geospatial data
- The Compute Layer: Where you process and analyze your data
- The AI Layer: How you use AI with your data
- The Semantics and IDs Layer: How you organize, use IDs, and collaborate with others
Let's go one by one.
For decades, the GIS industry has operated in data silos. Proprietary, complex formats meant that spatial data was “special”, locked away from the mainstream analytics world. This is a sovereignty liability.
But something fundamental has changed: the separation of compute and storage. With cloud object storage (S3 and compatible alternatives) now available both in public clouds and self-hosted environments, you can store your data wherever you want, and access it from multiple compute engines. This wasn’t possible in the monolithic GIS world.
Here’s the critical insight: this separation only delivers sovereignty if your data is in formats designed for this new reality. The first step toward geospatial sovereignty is making your spatial data cloud-native, not cloud-dependent, but cloud-native in format.
This means embracing open table formats like Apache Iceberg with GeoParquet for vector data. These aren’t just file formats, they’re full table specifications that let you store data once and use it many times, treating datasets like fully managed database tables for both transactional and analytical workloads. They support federation across multiple storage locations, enabling a truly distributed architecture, along with capabilities such as schema evolution, time travel, versioning, and partition pruning at massive scale.
As chair of the GeoParquet standards working group at OGC, I’ve seen firsthand how this convergence isn’t just about technical efficiency, it’s about strategic independence. Why does this matter? Because these formats break the GIS silo. They make geospatial data a first-class citizen in the modern analytics stack.
This results in the ability to store your vector data once in GeoParquet/Iceberg format on any S3-compatible storage ,whether that’s AWS S3, MinIO on-premise, or a sovereign cloud provider. Then also to process it with any engine: DuckDB for local analysis, BigQuery for cloud scale, Databricks for ML workloads, or PostgreSQL with spatial extensions. Same data, your choice of compute.
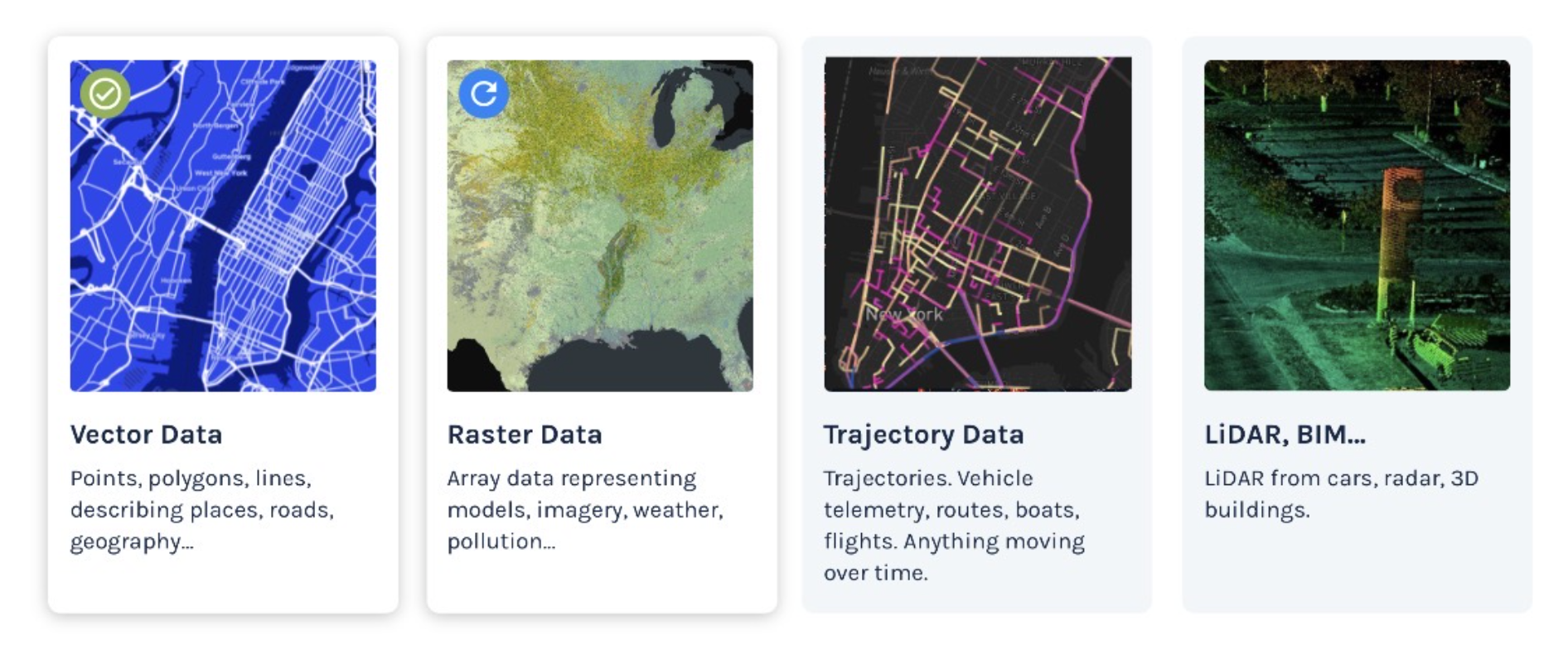
Not all geospatial data is ready yet. Vector data is standardized today. For raster data, at CARTO, we’re pushing for Raquet, bringing raster into the Iceberg ecosystem. Point clouds and trajectory data standards are coming. But the direction is clear: commitment to open table formats from the analytics community for maximum flexibility. This is where sovereignty begins.
The next layer is compute, where analysis happens. A common misconception is that “sovereignty” means “no cloud.” This is dangerously outdated, as Ukraine’s wartime migration of critical infrastructure to external clouds demonstrates.
The real breakthrough for sovereignty is that compute-storage separation through open table formats gives you the freedom to choose different compute engines and locations. Because your data lives in open formats like GeoParquet/Iceberg, you’re not locked into a single processing paradigm.
You can choose your engine based on your needs:
- Massive-Scale Cloud Analytics: Utilize BigQuery, Snowflake, or Databricks for analyzing vast datasets in a cloud environment.
- In-Process Analytics (Laptop/Edge): Opt for DuckDB for analytics performed directly within your application, on a laptop, or on edge servers.
- On-Premise Deployments: Choose PostgreSQL with spatial extensions for local infrastructure deployments.
Choose your location based on your requirements:
- Run sensitive workloads on-premise while leveraging the cloud for public data
- Use regional sovereign clouds (OVH in Europe, SITE) for data residency
- Burst to public cloud for peak loads while maintaining baseline capacity locally
This is the power of standardized distributed computing via open table formats. The same GeoParquet data in S3 can be processed by BigQuery for a national analysis or by DuckDB for a local government office; you decide based on data size, cost, and governance requirements.
For application layers like CARTO, deployment flexibility comes through Kubernetes, whether on managed cloud services or self-hosted clusters. But the real sovereignty comes from the compute-storage separation that lets you choose where your analysis runs.
Remember: when AWS US-East-1 went down, payment systems across Europe failed. With true compute flexibility, you can architect for resilience, not dependency.
The ultimate cost of failing to architect for resilience was made brutally clear in South Korea. Last October, a fire at a single national data center in Daejeon destroyed 858 terabytes of public data from ministries, universities, and hospitals. Why? Because the government's critical G-Drive system was deployed in that single location with no backup copy.
This single point of failure is the exact scenario Estonia's multi-location strategy is designed to prevent. It proves that for critical national data, even a secure domestic data center is a massive liability if it's your only one.
It’s also worth recognizing that this shift isn’t limited to on-premise or regional sovereign clouds. All major hyperscalers are now offering their own sovereign or sovereign-aligned models: AWS with its forthcoming European Sovereign Cloud, Google Cloud with its regional sovereignty controls and EU-based operations commitments, and Azure with its Cloud for Sovereignty programme. These initiatives show that sovereignty is becoming a mainstream cloud design principle. But the architectural lesson remains the same: whatever cloud, or combination of clouds, you choose, sovereignty comes from owning the data formats, computation model, and interfaces, not from relying on any single vendor’s sovereign-branded offering.
The future of geospatial is AI-driven. But there are two distinct AI transformations happening simultaneously, each with its own sovereignty implications. I explored both extensively in my recent keynote at the Spatial Data Science Conference on “The Agentic Revolution.”

We’re moving from clicking through interfaces to conversing with AI agents. Users will simply ask: “What’s the optimal location for our new warehouse?” or “Monitor construction progress in the northern district.” The agent handles the rest, accessing data, running analyses, and generating maps.
This presents a new sovereignty challenge: becoming dependent on a single AI provider or cloud-specific AI service that you can’t migrate or replace.
The critical requirement: use platforms that let you configure your own AI providers and models, not products that lock you into their cloud’s AI services. There is a de facto standard with the OpenAI-compatible completion API. And products like CARTO create AI proxies that translate any provider to a common language. This means you can:
- Use Gemini, OpenAI, or Anthropic when you need frontier capabilities
- Switch to open models like DeepSeek-V3 or Kimi K2 for cost efficiency
- Deploy local models via Ollama or vLLM for sensitive operations
For agent tooling, the emerging standard is MCP (Model Context Protocol), an open protocol that lets AI models interact with your data sources and tools in a standardized way. We’re now pushing for standardization of geospatial MCPs, so that spatial analysis tools from any provider can be used by any agent. Imagine agents that can seamlessly use routing tools from one vendor, geocoding from another, and spatial analytics from a third, all through standardized interfaces.
Open models are increasingly competitive. Silicon Valley’s hottest AI coding startups are now quietly building on Chinese open-source LLMs because the capability gap is now measured in months, not years. More importantly, these newer models often outperform frontier systems on the metric that matters most for agents: consistent tool use. When your workflow is “call routing API, wait, call geocoding API, validate polygon,” a 30-billion-parameter model that never invents phantom arguments beats a 1.8-trillion-parameter genius that occasionally hallucinated a new street.
But the sovereignty case goes beyond capability. Open models are inspectable, auditable, and deployable entirely within a nation’s trust boundary, crucial in an era where geopolitics is pushing governments toward internal self-sufficiency and, in Europe, toward deeper cross-border coordination. A reliable model you can run securely on your own infrastructure is already more strategically valuable than the next GPT refresh.
Beyond conversational agents, we’re seeing the emergence of specialized geospatial foundation models, AI trained specifically on Earth observation data, mobility patterns, or urban environments. These models power capabilities such as:
- Automatic building footprint extraction from satellite imagery
- Population dynamics prediction
- Environmental change detection
- Traffic flow modeling
Here too, sovereignty requires optionality. You might leverage Google’s foundation models for cutting-edge capabilities while maintaining access to open alternatives like NASA/IBM’s Prithvi for Earth observation or emerging models from the open community.
But the ultimate sovereignty play is building your own geospatial foundation models, either from scratch or by fine-tuning existing ones with your unique data. Imagine:
- A telecommunications company is combining base models with its QoS data to understand network performance patterns
- A nation training models on sensitive census data that could never leave its borders
- A utility company using decades of infrastructure data to predict failure points
This requires investment in model training capacity, but the AI ecosystem is rapidly democratizing these capabilities. With frameworks like PyTorch, distributed training infrastructure, and transfer learning techniques, building sovereign AI models is increasingly a question of organizational capacity rather than technical impossibility.
The sovereignty principle for AI is clear: always use standards (OpenAI-compatible APIs, MCP for tools) and platforms that give you provider choice. Never accept AI capabilities that work with only one model or one cloud. Your intelligence layer should be as portable as your data layer.
A sovereign geospatial stack isn’t just about controlling your infrastructure; it’s about ensuring you can participate in the global geospatial ecosystem. This requires something often overlooked: semantic standardization and common data models.
The geospatial world has historically been fragmented with different schemas, identifiers, and data models for the same real-world entities. This isn’t just inefficient; it’s a sovereignty risk. If your data can’t interoperate with global datasets, you’re isolated, not sovereign.
This is why semantic standardization is becoming critical. In my conversations with Peter Rabley, CEO of OGC, we’ve aligned on making this a priority. When everyone agrees on common identifiers and data models, geospatial becomes exponentially more powerful.
And semantics alone are not enough. You also need operational interfaces that allow systems to communicate in a consistent, portable way. This is where the OGC API family (Features, Tiles, Processes, Records) becomes strategically important. These modern, open, HTTP-native APIs give sovereign systems a shared way to expose and consume geospatial data and services across clouds, vendors, and borders. They ensure that even as nations strengthen control over infrastructure, they remain fully interoperable with the global geospatial ecosystem.
The Overture Foundation’s GERS IDs (Global Entity Reference System) exemplify this approach. By providing stable, global identifiers for places, they enable:
- Seamless data joining across sources
- Consistent entity resolution
- Simplified application development
- True data portability
Any sovereign strategy must ensure you’re not locked out of global collaboration. This means:
- Adopting common semantic standards so your national data can integrate with global datasets
- Contributing to open data initiatives like Overture, which has become one of the most comprehensive and frequently updated geospatial data sources
- Ensuring access to global observation programs like Copernicus for environmental monitoring
- Building on shared data models rather than proprietary schemas
Sovereignty means having control over your data while maintaining the ability to collaborate globally. Lock yourself into proprietary schemas or isolated data models, and you’ve confused isolation with independence.
National Digital Twins
Governments minting 1:1 digital replicas of their infrastructure, like Singapore's "Virtual Singapore", cannot let the master keys sit in a foreign cloud. These platforms are legally classified as Critical Information Infrastructure, sovereign assets by law and by risk profile.
Estonia’s model demonstrates the next-level solution: it treats its critical data (the population registry, land registry, etc.) as a national digital twin that is so vital, it must have a sovereign replica outside its own territory to ensure survival.
Critical Infrastructure Resilience
Telecom, power, and payment networks use geospatial data to reboot, reroute, and rebalance. When a cloud region fails, the map engine can go dark, stopping the flow of power or money. Sovereignty here is synonymous with uptime and resilience.
The South Korean data center fire is the ultimate case study in this failure, where 96 critical systems, including the government's online storage, were wiped out by a single physical event. This is resilience failing at a national scale.
Dual-Use Applications
The most compelling drivers bridge civil and defense needs. For example, the EU's Copernicus satellites provide data used by the European Border and Coast Guard Agency for surveillance, while Germany uses the exact same data to monitor drought and allocate agricultural subsidies. One dataset, two sovereign use cases, zero tolerance for export-control surprises.
AI-Assisted Decision Making
As AI drafts zoning laws, optimizes traffic grids, and plans evacuations, the question "who controls the intelligence?" becomes existential. When the model runs in another country's legal jurisdiction, "who owns the algorithm?" becomes a constitutional issue.
Whether you’re in Brussels crafting EU digital sovereignty policies, in Riyadh building Vision 2030’s spatial data infrastructure, or in São Paulo modernizing urban systems, the message is clear: the time to architect for sovereignty is now.
The building blocks now exist, even if many of them are still early and uneven in their maturity. The direction is clear, but the scale we ultimately need, national digital twins, sovereign AI ecosystems, and resilient multi-region infrastructures, will require continued investment and standardization. The path forward is to build on these beginnings, to invest in open standards through organizations like OGC, and to design modular, layered architectures that avoid single points of dependency.
This is how you have both innovation and independence.
The next generation of geospatial systems won’t be built on closed, monolithic platforms. They’ll be built on open foundations, with sovereignty designed in from the start.
The real question now is whether we, as a global geospatial community, will commit to building this open, sovereign, and resilient foundation together. CARTO is only one contributor among many, but like so many in this community, we stand ready to help build the shared infrastructure the next decade demands.










